SICP in Clojure - Chapter 5
In one of the previous blog posts I have announced that I would like to start a new series of posts. It is a persistent journal from my journey through aforementioned book. I hope that you will enjoy it and find it useful - the main goal is to make this series a place where we can return in future, recall ideas and thoughts that accompanied reading process.
Introduction
We are heading to the end of the book. It is the last chapter, and in the previous blog post I have already mentioned that last two chapters are really specific. And that is true, especially in terms of 5th chapter’s content.
High-level Convenience
Using high-level languages have many benefits. In terms of Clojure and other Lisp-like languages I would start with an automatic memory management and GC, various data structures or various optimizations, like tail-recursion etc. We do not think very often about how it is implemented, especially at the lowest level - in the hardware.
Can you imagine how the hardware should look like, to be capable of running code written in programming language from Lisp family? This is the main topic of the last chapter. Authors are starting with basic theory related to register machines and ending with the recipe for building a compiler. This blog post will be mostly theoretical, and instead of code examples, and exercises related with a topic “How to build a Clojure compiler”, we will take a peek under the hood, directly into the language implementation.
But first, let’s bring some definitions to the table.
What is a register machine?
Register machine is a type of a computer, which sequentially executes instructions. Those instructions are operating and modifying a set of a memory elements called registers. A typical operation will take operation arguments from registers, and it will push the result of that instruction to another register. When it comes to the designing of such machines, at first you need to create its data paths - which the wiring and placement of registers and defining possible operations. Of course we need someting which is supervising the execution process (e.g. preserving order) and that it is a responsibility of the controller.
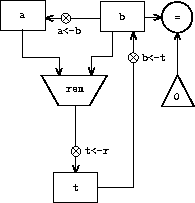
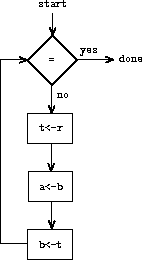
Example representation of register machine for calculating GCD - first image shows the data paths, second an example controller.
How to force the classic hardware to play nicely with functional programming languages?
Those representations of register machines, even if they are closer to hardware than usual functional code, are still require various tricks and techniques how to achieve convenience of high-level language at the lowest level. In the book authors presented couple of interesting concepts and their possible implementations for those machines.
Recursion and Tail Recursion
First concept explained in the chapter is recursion.
In order to handle properly recursion, register machine needs to implement instructions for save and restore values of registers in the stack data structure. Of course there is a problem of having such data structure and allocating memory for it.
That need can be partially fixed by optimizing recurrent calls which have property of being a tail call (it means that the same function invocation is a last instruction executed just before the end of that function). In that case there is no point of saving and restoring previous values from the stack, because it can reuse existing frame of reference and registers in the next call.
Data Structures
In the book, authors decided to implement lists as a tagged pair of value, and pointer to the next element. By a tagging authors mean using an additional type information for differentiate between different data structures.
Very important concept related with those data structures is memory representation. In the proposed implementation they have treated memory as the vector of cells, and each one has a unique address. Also, it depends on the use case, you can use the pointer arithmetic for calculating index values (either as an absolute address or based on base address with an offset).
Laziness, Infinite Collections and Streams
Everyone who deals with computers knows that an infinite collections (and in consequence - unlimited memory) is impossible. But you can create an illusion of that, by constantly reducing amount of unnecessary information. By transforming one element of an collection old values are unused anymore, also some parts of the program can be cleaned-up. In order to preserve this simple trick, you need take care of garbage collection.
Garbage Collection and Memory Management
This is a huge topic in itself, there are many algorithms which can be used for that - stop-and-copy, mark-and-sweep etc. The main purpose of that is to detect and clean up unused previously allocated objects, in order to preserve illusion of the infinite memory. Obviously, if the program will exhaust anyway available memory and it will use all of allocated objects without releasing them, GC will not help us at all.
As a side note, I would like to point out that if you will have to choose a single heritage of the Lisp language to the computer science, garbage collection will be a really a significant one, with no doubt.
Deconstructing Clojure
So instead of building our own Clojure compiler, we will go under the hood for a while. Do not worry, we will not go too deep into the internals, but hopefully we will get a better understanding about the language itself. I would like to focus on two topics - Clojure evaluation and data structures implementation available in the language, which are leveraging very interesting properties.
Is Clojure / ClojureScript interpreted or compiled?
Answer is like an usual one - it depends. It can be loaded dynamically directly to the JVM via load / eval (it is called a dynamic compilation) or compiled ahead of time to the Java bytecode, and then loaded into VM (it is called AOT compilation). But even in the case of dynamic compilation, you are preprocessing everything to the bytecode representation - the only difference is that it does not land in the file (it is generated during the run-time). As you may expected it means that VM does not understand Clojure or even Java languages directly - bytecode is a collection of class files. Each one contains description of a class and methods, which have been translated to intermediate representation suitable for JVM (you can find details here).
If we already have such code, then JVM loads, links and initializes class files provided during execution. During the first phase it finds a binary representation of the class and creates the VM internal representation from that. Then (during the linking phase) it adds prepared representations to the JVM state, and during that it also verifies is everything is structurally correct. At this point it also can resolve the symbolic references and it will prepare static fields, prefilled with the default variables. In the last step it invokes the initializers, but only when the class is needed (e.g. they are referenced by new or static method invocations, and obviously by associating it with the main class).
BTW. Sometimes I hear people complaining about the JVM start-up time, in terms of loading Clojure REPL’ - it has been already improved a lot, but if someone is interested in the details and why the Clojure (and not actually JVM) takes so long to bootstrap, I encourage you to dive deeper into those articles - 1, 2.
Situation is slightly simpler, when it comes to ClojureScript - it is always compiled to the JavaScript representation. But the compilation process is somehow interesting anyway. Under the hood, it uses Google Closure Compiler and if you are familiar with it, it requires a specific structure to be built in order preserve certain features, especially during the optimization phase. By leveraging the libraries, Google Closure Modules, specific dependency management, cljsc compiler can do amazing things - to name just one, dead code analysis which can prune properly even the external libraries code (assuming that external dependency somehow supports Google Closure as well). Obviously there is a trade-off - there are limitations, and if you want to do the most advanced optimizations you have to be compliant with them. That is the way how compiler can assume certain things and then safely do optimizations.
If you want grab a brief overview what kind of optimizations it can apply, I strongly suggest you to follow the tutorial from swanodette/hello-cljsc - at the end, there is a small example how enabling just {:optimizations :simple} can nicely optimize the initial source code. And there is still {:optimizations :advanced} mode. ![]()
Data Structures
If we will consider immutability in a functional programming world, we may think at first that having two values, before transformation and after it, can be very inefficient in terms of available resources. We need to preserve two copies in memory and probably spent some time on copying values from one place to another. That should especially true in Lisp-like languages, where data structures are our primary tool.
Those guarantees are really nice when it comes to the program analysis, but also from the compiler and optimization perspective. If that previous value is immutable and it will not change at all, we can leverage certain techniques of sharing parts of our collections between different values. We do not have to copy a whole collection, but only an updated part, where the old stuff can be just a reference (e.g. a pointer). It means that some collection persists on despite being created on top of another one.
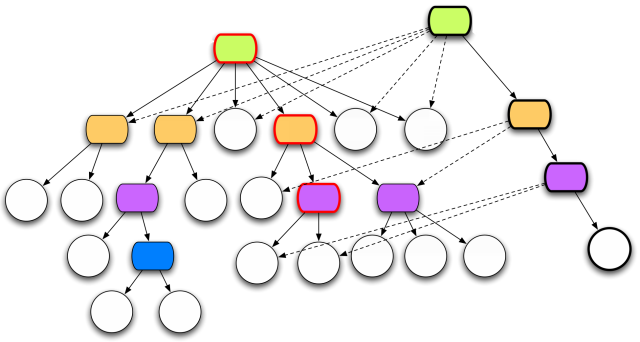
Image shamelessly taken from Rich Hickey's "Clojure Concurrency" talk.
This technique is called a structural sharing and it is thread and iteration safe way of reusing memory and reducing amount of necessary operations. All Clojure data structures are persistent (which means that they are shared), especially the hash maps, sets and vectors are based on top of very interesting concept called bit-partitioned hash tries. This is an enhanced concept of something called a hashed tree or trie, introduced by Phil Bagwell in that paper. The main change is related with the index values and bit-partitioning of hash codes, where a certain bit parts is responsible for indexing on a specific depth level of that tree. Details are really nicely explained in those two articles 1, 2.
Limitations of the JVM
Author of Clojure, Rich Hickey, even if he was pretty much very happy with using JVM (mostly because of platform maturity, tooling and libraries) presented also a pain points regarding the aforementioned choice.
The main issue is related with no tail call optimization. It affects other programming languages on top of JVM and each one solves that in a different way (e.g. sometimes by introducing an additional concepts like function annotations and generating trampolines - as it is done in Scala or Frege). Clojure attacks this problem from a different angle using loop and recur constructs which are really in phase with language philosophy. But for now, platform does not have support for that anyway, so under the hood it has to generate a loop or a any other suitable workaround.
Another pain point is related with use of Java’s boxed numbers and other math-related types. You have got plenty of options on JVM like Integer, Long, BigInteger etc., but by using you will inherit all problems related with choosing a proper type in Clojure as well. By relying on Clojure built-in types only, you will have problems related with interoperability between your code and JVM world, and you will have to deal with casting and types promotion by yourself. Another side-effect of that design is that it is also slower (because those numbers are really objects, and they are available on the heap). Having proper number types in the language, and hiding complexity of it inside compiler (related with optimizations or casting) could be really beneficial.
Summary
Over the course of five blog posts, we have went through whole book. We covered a lot of ground and prepared a lot of exercises from the book. We also learned Clojure during the process. If I have to choose the most interesting example from the book, I would go with the symbolic derivation or electronic circuit simulator. I did not change my opinion about the book - I still think that it is one of the most important publications for a computer scientist. Or for a programmer, who is just eager to learn and know more. Especially about functional programming.
I hope that you have enjoyed the series as much as I did. ![]()
Credits
- Structure and Interpretation of Computer Programs, Harold Abelson, Gerald Jay Sussman and Julie Sussman
- Full book available online
- clojure/clojure - Source code.
- swanodette/hello-cljsc
- Clojure, A Dynamic Programming Language for the JVM - Slides from Rich Hickey’s talk about Clojure internals.
- afronski/sicp-examples