Interesting Language Features - Erlang III
This blog post is a next article from a series which contains examples, explanations and details about interesting features of various programming languages. I have collected several examples of different characteristics, which definitely extended my view regarding programming, architecture and structure in general. I would love to hear your feedback about presented choices or description of yours favorite programming language feature.
Introduction
As you may know, In Erlang you are building systems which consists of multiple applications. Do not try to match these terms on the mainstream technologies (e.g. components) - you should rather compare it to the terms related with an operating system, because Erlang VM behaves in a similar way.
Erlang was designed long before the language of design patterns was formalized, but still engineers responsible for building the platform wanted to have a solid abstractions. It is all about splitting generic code away from specific code - and that is how the behaviors were created. They denote the idea that your specific code gives up its own execution flow and inserts itself as a bunch of custom functions (called callbacks) to be used by the generic code. In simpler words, behaviours handle the boring parts while you are focused on the business logic. In the case of applications, this generic part is quite complex and not nearly as simple as other behaviours. But on the first sight it does not look like this.
One of the parts in aforementioned complexity is an entity called application_controller. Whenever the VM starts up, this process is started and it starts applications. It supervises most of them (but not in the literal way). If you have couple of them, it will look like this:
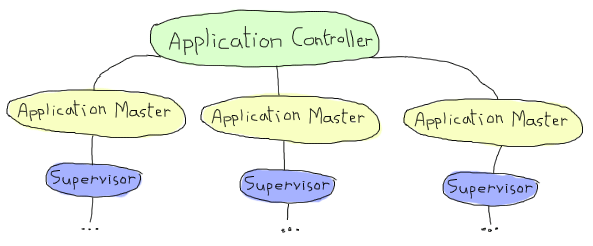 Image shamelessly taken from the amazing book Learn You Some Erlang For Great Good!
Image shamelessly taken from the amazing book Learn You Some Erlang For Great Good!
Everything that I have told you before you can find in the books (and again - I especially recommend the amazing book from @mononcqc - Learn You Some Erlang For Great Good!), but there is a small understatement regarding applications. ![]()

This topic arisen during work on my hobby project called afronski/wolves-and-rabbits-world-simulation. Above you can see the supervision tree of this application (pretty standard one), but at the beginning of it there are two additional processes - not just one, which I have expected (the application master). So I tried to found an explanation and literally - I found nothing. There is only a small mention about that in the aforementioned book:
The application master is in fact two processes taking charge of each individual application: they set it up and act like a middleman in between your application's top supervisor and the application controller.
But that’s all. No particular explanation why the second process is necessary. This topic is missing in the Erlang books that I know - if you know a book with a good explanation of this, please let me know in the comments - it can be beneficial for me (and as an additional reference).
So, I thought that it is an interesting topic to analyze and I started to dig into it.
Internals
So, we know what the application controller is, what the application master is explained above in the quote. In other words application master behaves like an application nanny: ![]()
Just know that the application master acts a bit like the app's nanny (well, a pretty insane nanny). It looks over its children and grandchildren, and when things go awry, it goes berserk and terminates its whole family tree. Brutally killing children is a common topic among Erlangers.
Nanny or not - still we don’t know why there are actually two of them. If there is no explanation in the books, we need to look at the actual source code. And finally we found something useful.
%%% The logical and physical process structure is as follows:
%%%
%%% logical physical
%%%
%%% -------- --------
%%% |AM(GL)| |AM(GL)|
%%% -------- --------
%%% | |
%%% -------- --------
%%% |Appl P| | X |
%%% -------- --------
%%% |
%%% --------
%%% |Appl P|
%%% --------
%%%
%%% Where AM(GL) == Application Master (Group Leader)
%%% Appl P == The application specific root process (child to AM)
%%% X == A special 'invisible' process
%%%
%%% The reason for not using the logical structrure is that
%%% the application start function is synchronous, and
%%% that the AM is GL.
%%%
%%% This means that if AM executed the start
%%% function, and this function uses io, deadlock would occur.
%%% Therefore, this function is executed by the process X.
%%%
%%% Also, AM needs three loops;
%%% - init_loop (waiting for the start function to return)
%%% - main_loop
%%% - terminate_loop (waiting for the process to die)
%%% In each of these loops, io and other requests are handled.But what is a group leader? Let’s dig into official documentation:
Every process is a member of some process group and all groups have a group leader. All IO from the group is channeled to the group leader. When a new process is spawned, it gets the same group leader as the spawning process. Initially, at system start-up, init is both its own group leader and the group leader of all processes.
Aha! Now the actual structure is pretty clear. During the application:start/2 anything can happen, including I/O calls - but application master is a group leader, owner of I/O resources in its supervision tree. If the I/O calls are channeled through leader, definitely a deadlock can occur if the same process is responsible for invoking that a call. In order to avoid that OTP developers introduced an artificial process called X in the comment above, which executes the start function. Thanks to that, any I/O calls from the start-up process can be forwarded through the application master safely. ![]()
What is even more interesting, an application life cycle consists of three phases - init_loop which is responsible for waiting until the start-up process will finish, main_loop which is a normal work of an application and terminate_loop which is responsible for shutdown all process owned by an application.
We finally found an useful explanation for the additional processes in the supervision tree. Besides that, we introduced behaviors, which are the primary mechanism where it comes to reusing common abstractions prepared by the OTP team. But we, as the developers, can also create our own behaviors - and we will cover this topic in the next post.